
AI 简史:从神经元到现代大模型
人工智能 (AI) 和深度学习 (DL) 在过去的几十年中飞速发展,推动了计算机视觉、自然语言处理和机器人等领域的进步。今年的诺贝尔物理学奖更是颁给了美国科学家约翰·霍普菲尔德 (John Hopfield)和英国科学家杰弗里·辛顿(Geoffrey Hinton),表彰他们“在人工神经网络机器学习方面的基础性发现和发明”。本文将为大家概述 AI 的发展历程,梳理出从早期神经网络模型到现代大型语言模型发展过程中的重要里程碑。

图 1. AI 发展全景图
1. 人工智能诞生 (1956)
人工智能(AI)的概念由来已久,但现代 AI 的雏形是在 20 世纪中期逐渐形成的。“人工智能”这个术语是由计算机科学家和认知科学家约翰·麦卡锡 (John McCarthy) 在 1956 年召开的达特茅斯人工智能夏季研讨项目上首次提出并被大家接受,AI 从此走上历史舞台。

图 2.
A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence (1955)
达特茅斯会议通常被视为 AI 研究的发源地。这次会议汇聚了计算机科学家、数学家和认知科学家,共同探讨创造能够模拟人类智能的机器的可能性。与会者中大佬云集,包括:
-
约翰·麦卡锡 (John McCarthy) :计算机科学家、Lisp 编程语言发明人之一。
-
马文·明斯基 (Marvin Minsky):计算机科学家、框架理论的创立者。
-
雷·索洛莫诺夫 (Ray Solomonoff):算法概率论创始人,通用概率分布之父,通用归纳推理理论的创建者。
-
纳撒尼尔·罗切斯特 (Nathaniel Rochester) :IBM 701 的首席设计师,编写了世界上第一个汇编程序。
-
克劳德·香农 (Claude Shannon) :数学家、发明家、密码学家,信息论创始人。
-
奥利弗·塞弗里奇 (Oliver Selfridge):模式识别的奠基人、人工智能的先驱,被誉为“机器知觉之父”。

图 3. 参加达特茅斯会议的部分重量级人物
达特茅斯会议对计算机科学的发展产生了深远的影响,它为计算机科学的发展指明了方向,推动了计算机科学的快速发展。会议的成果为后来的计算机科学研究提供了重要的思想和方法支持,为计算机科学的教育和培训提供了重要的参考。达特茅斯会议也为跨学科合作和交流提供了一个成功的范例,为后来的跨学科研究提供了重要的经验和启示。
2. AI 的演进:从基于规则的系统到深度神经网络
纵观整个 AI 的发展史,有一条清晰的发展脉络,那就是从基于规则的系统向深度神经网络的不断进化。
人工智能 (AI) 的发展始于上个世纪 50 年代,那时人们开始开发用于国际象棋和问题求解的算法。第一个 AI 程序 Logical Theorist 于 1956 年诞生。到了 1960 和 1970 年代,基于规则的专家系统如 MYCIN 被引入,它们可以帮助进行复杂的决策。1980 年代,机器学习开始兴起,使 AI 系统能够从数据中学习并不断改进,为现代深度学习技术奠定了基础。
今天,大多数最前沿的 AI 技术都由深度学习驱动,深刻改变了 AI 的发展格局。深度学习是机器学习的一个独立分支,它通过多层人工神经网络从原始数据中提取复杂特征。在本文中,我们将探讨 AI 的发展历史,并重点介绍深度学习在其中的关键作用。

图 4. 人工智能、机器学习、神经网络、深度学习之间的关系
3. 早期人工神经网络 (1940s – 1960s)
3.1 McCulloch-Pitts 神经元 (1943)
神经网络的概念可以追溯到 1943 年,当时 Warren McCulloch 和 Walter Pitts 提出了第一个人工神经元模型。McCulloch-Pitts (MP) 神经元模型是对生物神经元的一种突破性简化。这个模型通过聚合二进制输入,并利用阈值激活函数来做出决策,从而为人工神经网络奠定了基础,输出结果为二进制
{
0
,
1
}
{0, 1}
{0,1}。
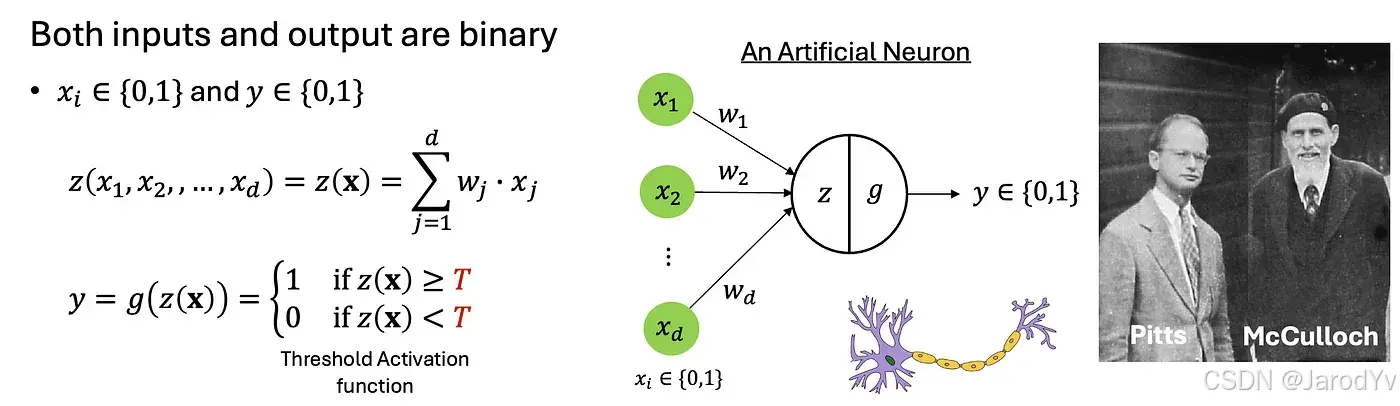
图 5. 人工神经元的结构与原理
这种简化的模型抓住了神经元行为的核心特征——接收多个输入,整合这些输入,并根据是否超过阈值来产生二进制输出。尽管MP神经元模型非常简单,但它能够实现基本的逻辑运算,展示了神经计算的潜力。
3.2 Rosenblatt 感知机模型 (1957)
Frank Rosenblatt 在 1957 年引入了感知机,这是一种能够学习和识别模式的单层神经网络。感知机模型比 MP 神经元更为通用,设计用于处理实数值输入,并通过调整权重来最小化分类错误。
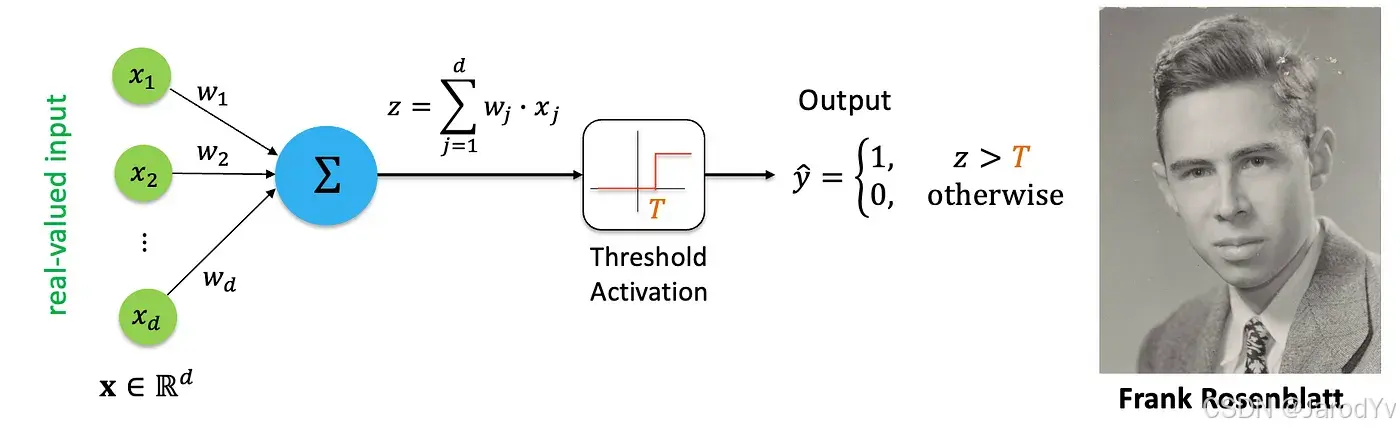
图 6. 感知机模型
Rosenblatt 还为感知机开发了一种监督学习算法,使得网络能够直接从训练数据中进行学习。
L
(
W
)
=
−
∑
i
∈
M
W
T
X
i
y
i
mathcal{L}(W) = – sum_{i in M} W^T X_i y_i
L(W)=−i∈M∑WTXiyi
图 7. Mark I 感知机,是一台实现了图像识别感知机算法的机器
Rosenblatt 的感知机展示出识别个人和在不同语言间翻译语音的潜力,这在当时引发了公众对 AI 的极大兴趣。感知机模型及其相关的学习算法成为神经网络发展历程中的重要里程碑。然而,很快就显现出一个关键限制:当训练数据是非线性可分时,感知机的学习规则无法收敛。
3.3 ADALINE (1959)
Widrow 和 Hoff 在 1959 年引入了 ADALINE(自适应线性神经元,也称 Delta 学习规则),对感知机学习规则进行了改进。ADALINE 解决了二进制输出和噪声敏感性等限制,并能够学习并收敛非线性可分的数据,这是神经网络发展中的一大突破。

图 8. ADALINE VS. 感知机
ADALINE 的主要特点包括:
- 线性激活函数:不同于感知器的阶跃函数,ADALINE 使用线性激活函数,因此适用于回归任务和连续输出。
- 最小均方(LMS)算法:ADALINE 采用 LMS 算法,该算法通过最小化预测输出与实际输出之间的均方误差,提供更高效和稳定的学习过程。
- 自适应权重:LMS 算法根据输出误差自适应调整权重,使 ADALINE 即使在有噪声的情况下也能有效地学习和收敛。
ADALINE 的引入标志着神经网络第一次黄金时代的开始,它克服了 Rosenblatt 感知机学习的限制。这一突破实现了高效学习、连续输出和对噪声数据的适应能力,推动了该领域的创新和快速发展。

图 9. ADALINE 开启了神经网络第一次黄金时代
然而,与感知机类似,ADALINE 仍然无法解决线性可分的问题,无法应对更复杂的非线性任务。这一局限集中体现在异或(XOR)问题上,也促进了更高级神经网络架构的发展。
3.4 异或(XOR)问题 (1969)
1969年,Marvin Minsky 和 Seymour Papert 在他们的著作《Perceptrons》中揭示了单层感知机的一个重要局限:由于其线性决策边界,感知机无法解决异或 (XOR) 问题,而这是一个简单的二元分类任务。异或问题不是线性可分的,也就是说,没有一个单一的线性边界能够正确地将所有的输入模式分类。

图 10. Marvin Minsky 和 Seymour Papert 合著的《Perceptrons: An introduction to computational geometry》
这一发现强调了需要开发更复杂的神经网络架构,以便能够学习非线性的决策边界。感知机的局限性被揭露后,人们对神经网络的信心减弱,转而研究符号人工智能方法,这标志着从 20 世纪 70 年代初到 80 年代中期的“神经网络的第一次黑暗时代”的开始。

图 11. 异或问题将神经网络代入第一次黑暗时代
然而,研究人员从解决异或问题中获得的见解促使他们意识到需要更复杂的模型来捕捉非线性关系。这种认识最终推动了多层感知机和其他先进神经网络模型的发展,为神经网络和深度学习在后来的复兴奠定了基础。
4. 多层感知机 (1960)
多层感知机 (MLP) 最早于 20 世纪 60 年代提出,作为对单层感知机的改进。MLP 由多个层次的相互连接的神经元组成,能够克服单层模型的局限性。苏联科学家 A. G. Ivakhnenko 和 V. Lapa 在感知机基础上进行研究,对多层感知机的发展中做出了重要贡献。

图 12. 多层感知机模型
4.1 隐藏层 (Hidden Layers)
增加隐藏层使得 MLP (多层感知器) 可以捕捉和表达数据中的复杂非线性关系。这些隐藏层极大地增强了网络的学习能力,使其能够解决诸如异或问题这样非线性可分的问题。

图 13. 隐藏层解决异或问题
4.2 多层感知机的历史背景与挑战
MLP 的出现标志着神经网络的研究向前迈出了重大一步,展示了深度学习架构在解决复杂问题方面的潜力。然而,在 1960 年代和 1970 年代,MLP 的发展面临若干挑战:
- 缺乏训练算法:早期的 MLP 模型缺乏高效的训练算法,无法有效地调整网络权重。此时反向传播算法还未诞生,训练多层深度网络非常困难。
- 算力限制:当时的算力不足以应对训练深度神经网络所需的复杂计算。这一限制拖慢了 MLP 的研究和发展进程。
神经网络的第一个黑暗时代在 1986 年结束,随着反向传播算法的诞生,开启了神经网络的第二个黄金时代。
5. 反向传播 (1970s – 1980s)
1969 年,异或问题揭示了感知机(单层神经网络)的局限性。研究人员意识到,多层神经网络能够克服这些限制,但缺乏有效的训练算法。17年后,反向传播算法的开发使得神经网络在理论上可以逼近任何函数。值得注意的是,该算法实际上在发表之前就已被发明。如今,反向传播已成为深度学习的核心组件,自 20 世纪 60 年代和70 年代以来经历了显著的发展和完善。

图 14. 反向传播原理示意图
反向传播的关键特性:
- 梯度下降:反向传播与梯度下降联合使用以降低误差函数。该算法计算每个权重相对于误差的梯度,从而逐步调整权重以减少误差。
- 链式法则:反向传播算法的核心在于应用微积分的链式法则。此法则使得误差的梯度可以被分解为一系列偏导数,并通过网络的反向传递高效计算。
- 分层计算:反向传播逐层运作,从输出层向输入层反向传递。这种分层计算确保梯度在网络中正确传播,使得深度架构的训练成为可能。
5.1 早期发展 (1970 年代)
- Seppo Linnainmaa (1970): 提出了自动微分的概念,这是反向传播算法的重要组成部分。
- Paul Werbos (1974): 提议使用微积分的链式法则计算误差函数对网络权重的梯度,从而能够训练多层神经网络。
5.2 强化与普及(1980 年代)
- David Rumelhart, Geoffrey Hinton 和 Ronald Williams (1986): 将反向传播这一高效实用的方法,用于训练深度神经网络,并展示了其在多种问题中的应用。

图 15. 反向传播算法的三位主要贡献者
其中 Geoffrey Hinton 因其在人工神经网络和机器学习领域的贡献获得了 2018 年图灵奖和 2024 诺贝尔物理学奖,称为继 Herbert Simon 后第二位图灵奖-诺贝尔奖双料得主。
5.3 通用逼近定理 (1989)
George Cybenko 在 1989 年提出的通用逼近定理,为多层神经网络的功能提供了数学基础。该定理表明,只要神经元数量足够,并且使用非线性激活函数,具有单个隐藏层的前馈神经网络就能够以任意精度逼近任意连续函数。这个定理突显了神经网络的强大能力和灵活性,使其能够应用于各种领域。

图 16. 具有单个隐藏层的神经网络可以将任意连续函数逼近到任意所需的精度,从而在各个领域解决复杂的问题
5.4 第二次黄金时代 (1980 年代末 – 1990 年代初)
**反向传播算法的出现和通用逼近定理的提出,开启了神经网络研究的第二个黄金时代。**反向传播提供了一种高效的多层神经网络训练方法,使研究人员能够构建更深层次和更复杂的模型。通用逼近定理则为使用多层神经网络提供了理论支持,并增强了人们对其解决复杂问题能力的信心。在 1980 年代末至 1990 年代初,这一时期见证了对神经网络领域的兴趣回升和显著的进步。

图 17. 反向传播和通用逼近定理开启了神经网络研究的第二个黄金时代
5.5 第二次黑暗时代 (1990 年代初 – 2000 年代初)
然而,由于一系列因素,神经网络领域在 1990 年代初至 2000 年代初经历了“第二个黑暗时代”:
- 支持向量机 (SVM) 的兴起:支持向量机为分类和回归任务提供了更优雅的数学方法。
- 算力限制:由于训练深度神经网络仍然耗时且对硬件要求高,计算能力受到限制。
- 过拟合和泛化问题:这两个问题导致早期神经网络在训练数据上表现良好,但在新数据上表现不佳,限制了其实用性。
这些挑战使得许多研究人员转而关注其他领域,导致神经网络研究的停滞。

图 18. 随着 SVM 的兴起,神经网络进入第二个黑暗时代
深度学习的复兴 (2000 年代末 – 现在)
在 2000 年代末和 2010 年代初,神经网络领域经历了复兴,这得益于以下方面的进步:
- 深度学习架构的发展(如 CNNs、RNNs、Transformers、Diffusion Models)
- 硬件的改进(如 GPUs、TPUs、LPUs)
- 大规模数据集的可用性(如 ImageNet、COCO、OpenWebText、WikiText 等)
- 训练算法的优化(如 SGD、Adam、dropout)
这些进展带来了计算机视觉、自然语言处理、语音识别和强化学习的重大突破。通用逼近定理与实际技术的进步相结合,为深度学习技术的广泛应用和成功奠定了基础。
6. 卷积神经网络 (1980s – 2010s)
卷积神经网络 (CNN) 在深度学习领域,尤其是计算机视觉和图像处理方面,带来了革命性的变化。从上个世纪 80 年代到本世纪最初的 10 年,CNN 在架构、训练技术和应用等方面取得了显著的进步。
卷积神经网络由以下三个主要组件构成:
- 卷积层 (Convolutional Layers):这些层通过一组可调整的滤波器,从输入图像中自动学习和提取特征的空间层次结构。
- 池化层 (Pooling Layers):池化层通过缩小输入的空间尺寸,来提高对输入变化的适应性,并减少计算量。
- 全连接层 (Fully Connected Layers):在卷积层和池化层之后,全连接层用于分类任务,负责整合之前层中提取的特征。
卷积神经网络的主要特性
- 局部感受野:CNN 利用局部感受野来捕捉输入数据中的局部特征,使其在处理图像和其他视觉任务时表现出色。
- 权重共享:通过在卷积层中共享权重,CNN 能够减少网络中参数的数量,从而提高训练效率。
- 平移不变性:池化层赋予网络平移不变性,使其能够识别输入图像中不同位置的相同模式。
6.1 早期发展 (1980 – 1998)
1980 年代,福岛邦彦 (Kunihiko Fukushima) 首次提出了 CNN 的概念,他设计了一种称为神经认知机 (Neocognitron) 的分层神经网络,这种网络模仿了人类视觉皮层的结构。这项开创性的研究为之后 CNN 的发展奠定了基础。

图 19. 福岛邦彦与他的神经认知机
到了 1980 年代末和 1990 年代初,Yann LeCun 和他的团队在此基础上进一步发展了 CNN,并推出了 LeNet-5 架构,该架构专为手写数字识别而设计。
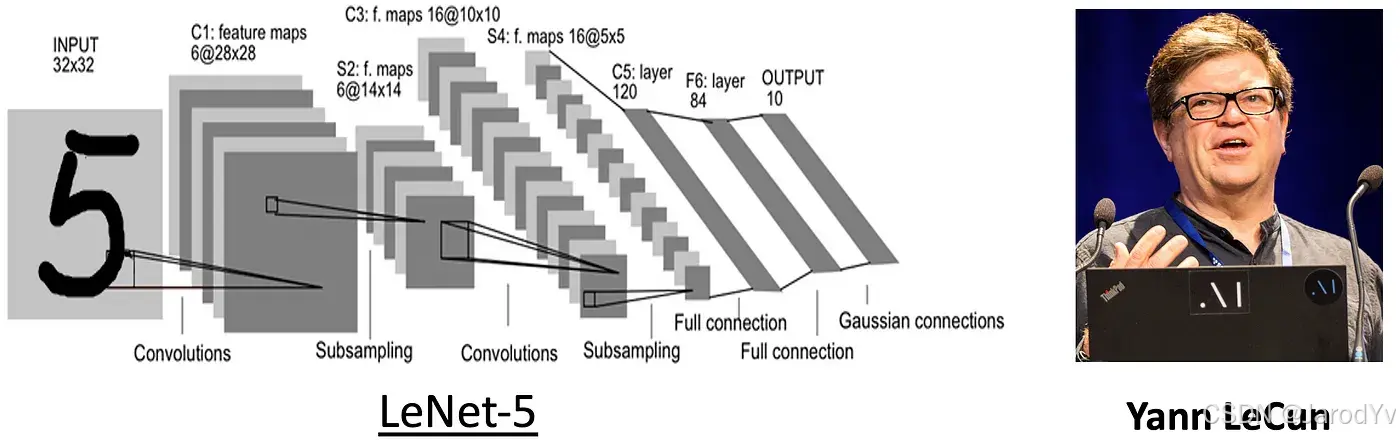
图 20. Yann LeCun 与他的 LeNet-5
6.2 CNN 的崛起:AlexNet (2012)
2012 年,AlexNet 在 ImageNet 大规模视觉识别挑战赛(ILSVRC)中取得了重大胜利,这是 CNN 发展中的一个重要里程碑。这次胜利不仅以压倒性优势赢得了比赛,也在图像分类领域取得了重大突破。

图 21. ILSVRC 历年冠军及其表现
ILSVRC 是一个年度图像识别基准测试,用于评估算法在一个包含 1000 万多张注释图像的数据集上的表现,这些图像被划分为 1000 个类别。AlexNet 的创新之处包括:
- ReLU 激活函数:为解决传统激活函数的问题而引入,ReLU 提高了训练速度并改善了性能。
- Dropout 正则化:这种技术通过在训练过程中随机丢弃神经元来减少过拟合现象。
- 数据增强:通过人为增加训练数据的多样性,增强了数据集的丰富性,从而改善了模型的泛化能力。
AlexNet 的成功成为 CNN 发展中的一个转折点,为图像分类和物体检测的进一步发展奠定了基础。
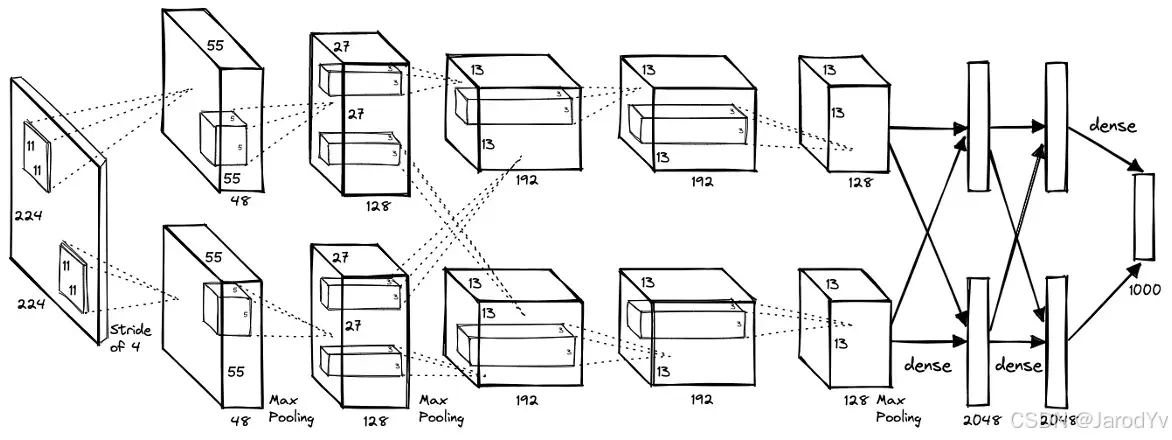
图 22. AlexNet 架构
6.3 AlexNet 开启神经网络的第三次黄金时代(2010 年代至今)
自 2010 年代直至今天,当前的科技发展黄金时代以深度学习、大数据和强大计算平台的结合为特征。在这一时期,图像识别、自然语言处理和机器人技术等领域取得了显著的突破。持续的研究不断推动着人工智能(AI)能力的边界。

图 23. AlexNet 开启神经网络的第三次黄金时代
6.4 后续架构改进
继 AlexNet 之后,又相继出现了几个有影响力的架构:
-
VGGNet (2014):由牛津大学的视觉几何组开发,VGGNet 强调使用更深的网络架构,并采用较小的卷积滤波器 (
3
×
3
3 times 3
3×3),从而取得了显著的准确率。

图 24. 原始 VGGNet 架构
-
GoogLeNet/Inception (2014):引入了 inception 模块,使得网络能够以更高效的方式捕捉不同尺度的特征。

图 25. GooLeNet 架构
-
ResNet (2015):残差网络通过引入跳跃连接,使得训练非常深的网络成为可能,同时缓解了梯度消失问题。

图 26. ResNet 架构
6.5 CNN 的应用
CNN 的进步已经在多个领域引发了变革:
- 计算机视觉:CNN 已成为现代计算机视觉的核心,实现了图像分类、物体检测和语义分割方面的突破。
- 医学影像:CNN 被用于疾病诊断、肿瘤检测和图像引导手术等任务,大大提高了诊断准确性。
- 无人驾驶:CNN 是无人驾驶感知系统的核心,使它们能够解释和响应周围环境。
CNN 从其创立到目前作为深度学习基石的历程展示了其对 AI 的重大影响。CNN 的成功也为深度学习的进一步进步铺平了道路,并激发了其他专用神经网络架构的发展,如 RNN 和 Transformer。CNN 的理论基础和实际创新显著推动了深度学习技术在各个领域的广泛应用和成功。
7. 循环神经网络 (1986 – 2017)
循环神经网络 (RNN) 是为了处理序列数据而设计的。与传统的前馈网络(MLP)不同,RNN 拥有一个内部的隐藏状态或“记忆”,使其能够捕捉序列元素之间的时间依赖性。因此,RNN 在语言建模、时间序列预测和语音识别等任务中尤为有效。
7.1 早期发展 (1980s – 1990s)
RNN 的概念起源于 1980 年代,John Hopfield, Michael I. Jordan 和 Jeffrey L. Elman 等先驱为这些网络的发展做出了贡献。John Hopfield在 1982 年提出的 Hopfield 网络为理解神经网络中的循环连接奠定了基础。Jordan 网络和 Elman 网络分别在 1980 年代和 1990 年代提出,是早期捕捉序列数据中时间依赖性的尝试。

图 27. RNN 架构
RNN 使用历时反向传播 (BPTT) 进行训练,这是前馈网络标准反向传播算法的扩展。BPTT 需要将网络在时间上展开,将每个时间步视为一层。在前向传播时,输入序列被处理,并在输出层计算误差。然后,产生的梯度从最后一个时间步反向传播到第一个时间步,以更新 RNN 的参数。然而,由于梯度消失问题,RNN 在学习长时间依赖性时遇到困难,因为梯度会变得极小,导致无法学习。相反,梯度也可能变得过大,造成训练不稳定,这被称为梯度爆炸问题。

图 28. 反向传播 (BPTT)
7.2 LSTM, GRU 和 Seq2Seq 模型 (1997 – 2014)
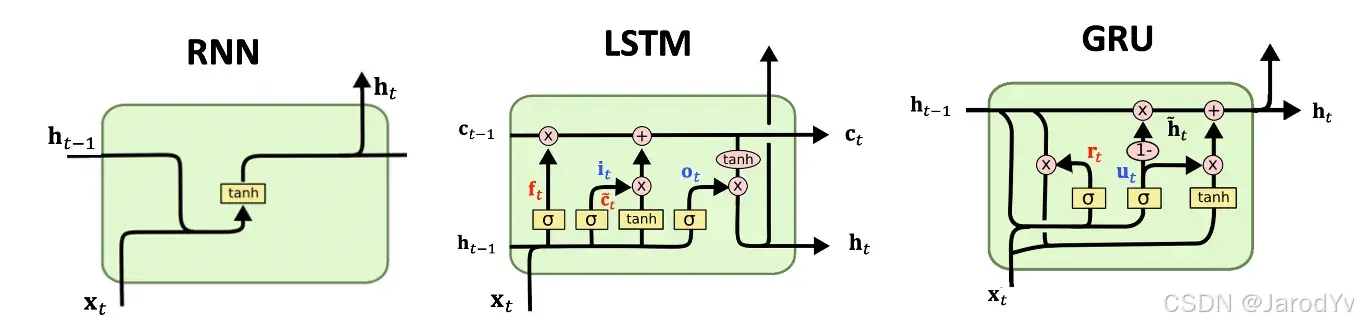
图 29. RNN, LSTM, GRU 单元
-
长短期记忆 (LSTM) 网络 (1997):Sepp Hochreiter 和 Jürgen Schmidhuber 提出了 LSTM 网络,以解决传统 RNN 中的梯度消失问题。LSTM 通过使用门控机制来控制信息流动,使其能够捕捉序列数据中的长期依赖关系。LSTM 包括单元状态(用于存储长期信息)、隐藏状态(携带当前时间步的短期输出),以及三个门(输入门、遗忘门和输出门)。在每一步中,LSTM 会根据多个数学运算和门来决定需要遗忘多少信息,向单元状态添加多少信息,以及为下一步输出多少信息。
-
门控循环单元 (GRU) (2014):Kyunghyun Cho 等人提出了 GRU,这是一种简化版的 LSTM,也采用门控机制来调节信息流。与 LSTM 的三个门和两个状态不同,GRUs 只有两个门和一个状态。LSTM 的遗忘门和输入门被合并为一个更新门,用于决定保留多少过去的信息和整合多少新信息。此外,GRU 用重置门代替了 LSTM 的输出门,该门决定在整合新信息之前需要“重置”或忘记多少过去的信息。由于 GRU 的参数较少,通常训练速度更快。
-
Seq2Seq 模型 (2014):Ilya Sutskever 和他的团队提出了 Seq2Seq 模型,这种模型使用编码器-解码器架构,将输入序列转换为输出序列。Seq2Seq 模型已被广泛应用于机器翻译、语音识别和文本摘要等任务。
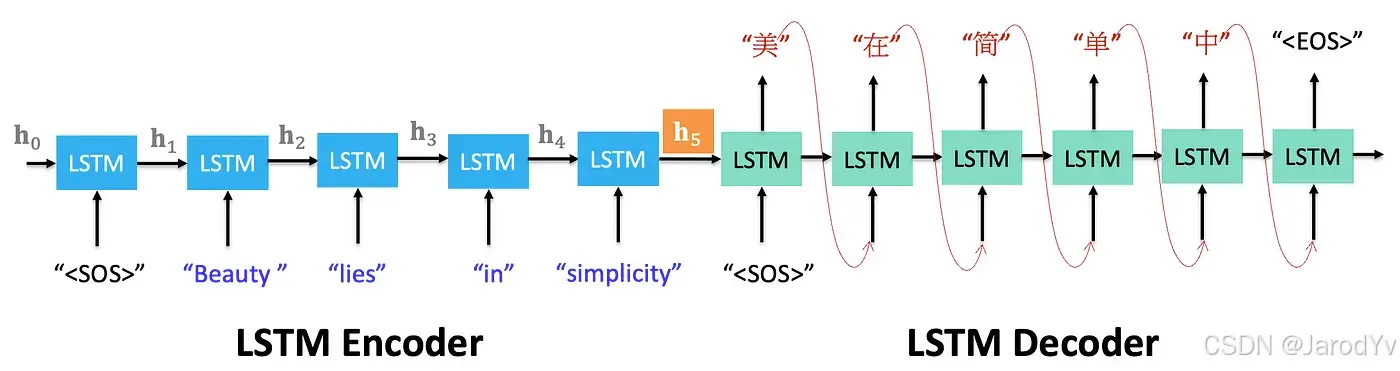
图 30. 基于 LSTM 的 Seq2Seq 编码器-解码器架构
7.3 RNN 的应用
RNN 在多个领域产生了重大影响,包括:
- 自然语言处理:RNN 在自然语言处理领域引发了革命性变化,使得语言建模、机器翻译、情感分析和文本生成等任务取得了显著进展。
- 语音识别:RNN 广泛用于语音识别系统中,它们通过建模口语的时间依赖性,将语音信号转换为文本。
- 时间序列预测:RNN 在时间序列预测中表现出色,它们通过建模顺序数据的时间依赖性,以预测未来值。
7.4 RNN 的挑战
尽管 RNN 在许多方面取得了成功,但其仍面临若干挑战:
- 梯度消失与梯度爆炸:传统 RNN 在处理这些问题时表现不佳,尽管 LSTM 和 GRU 提供了一些解决方案。
- 计算复杂性:训练 RNN 可能需要大量资源,尤其是在处理大型数据集时。
- 并行化:RNN 的顺序特性使得并行训练和推理过程变得复杂。
RNN 的成功为深度学习的进一步发展奠定了基础,并启发了其他专门化神经网络架构的发展,例如 Transformer,它们在各种序列数据任务中取得了最先进的性能。RNN 的理论基础和实际创新大大推动了深度学习技术在各个领域的广泛应用和成功。
8. Transformer (2017 – 现在)
Transformer 以其卓越的序列数据处理能力,深刻地改变了深度学习的格局,并在自然语言处理 (NLP) 和计算机视觉等多个领域中发挥了重要作用。
8.1 Transformer 简介
Vaswani 等人于 2017 年发表了开创性论文“Attention is All You Need”,其中提出了 Transformer 模型。这个模型放弃了 RNN 的传统序列处理方式,转而采用自注意力机制,从而实现了并行处理,并能更好地处理长距离依赖关系。
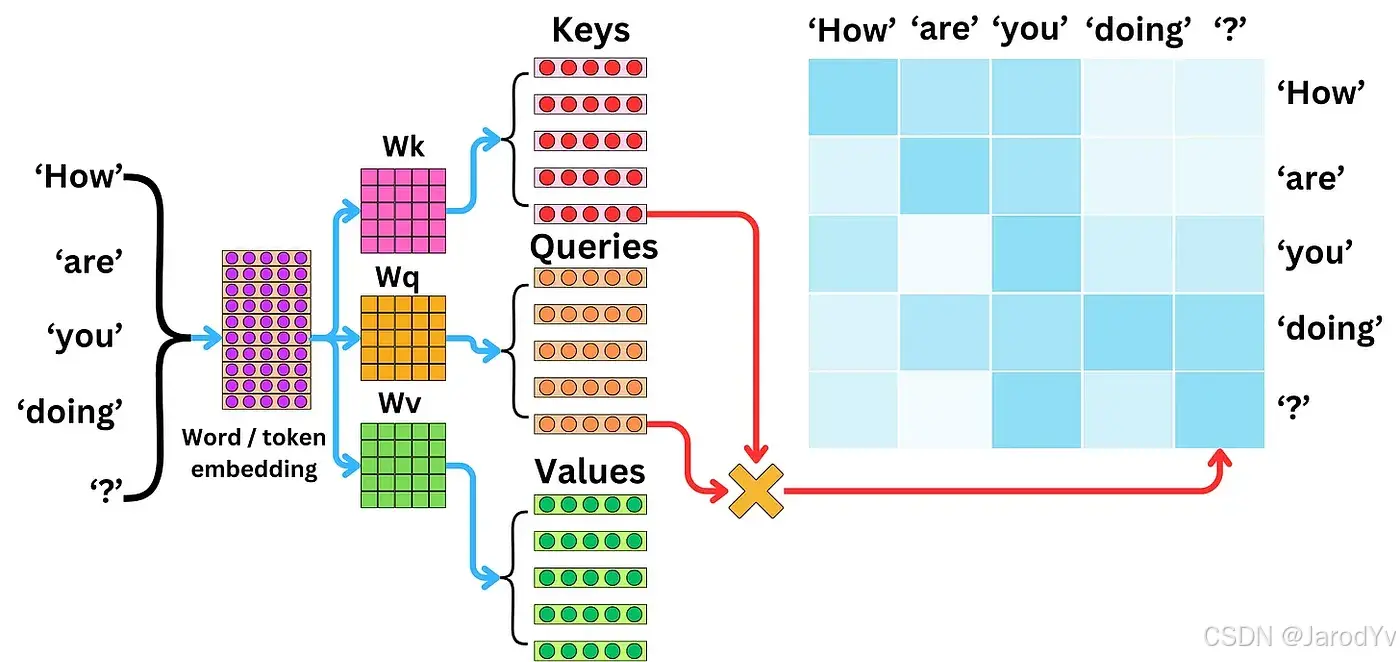
图 31. 自注意力机制
Transformer 具有如下核心特性:
- 自注意力机制:允许序列中每个位置灵活地关注其他所有位置,从而比 RNN 或 LSTM 更有效地捕捉上下文。
- 并行化:通过同时处理所有输入数据,大大提高了训练速度,这与 RNN 的顺序处理方式形成鲜明对比。
- 编码器-解码器结构:编码器和解码器堆栈都使用自注意力和前馈神经网络层,并通过位置编码来保持序列的顺序。

图 32. Transformer 架构
关于 Transformer 和自注意力机制的详细介绍,请参考 《深度解析 Transformer 和注意力机制(含完整代码实现)》 和 《图解 NLP 模型发展:从 RNN 到 Transformer》。
8.2 Transformer 的衍生模型
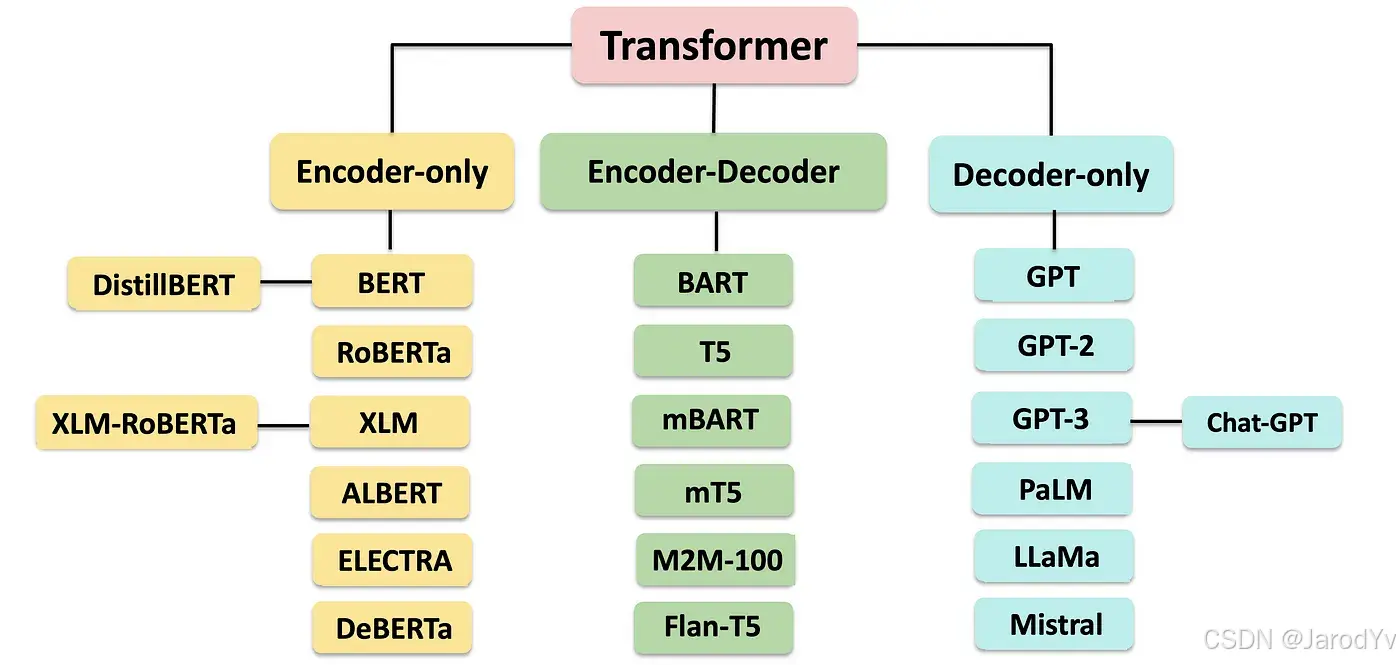
图 33. 基于 Transformer 的模型
Transformer 有众多衍生模型,其中比较重要的有:
- BERT (2018): BERT 是一种仅使用编码器的双向编码器表示模型,通过掩码语言建模和下一句预测的预训练,彻底革新了 NLP。
- GPT (2018): GPT 旨在预测序列中的下一个 Token(词),展示了在理解和生成类人文本方面的强大能力。这一基础模型为生成式语言模型的后续发展奠定了基础,展示了从大型文本语料库中进行无监督学习的潜力。
- T5 (2019): T5 是一种编码器-解码器结构的文本到文本转换模型,将 NLP 任务转化为统一的文本到文本格式,简化了模型架构和训练过程。
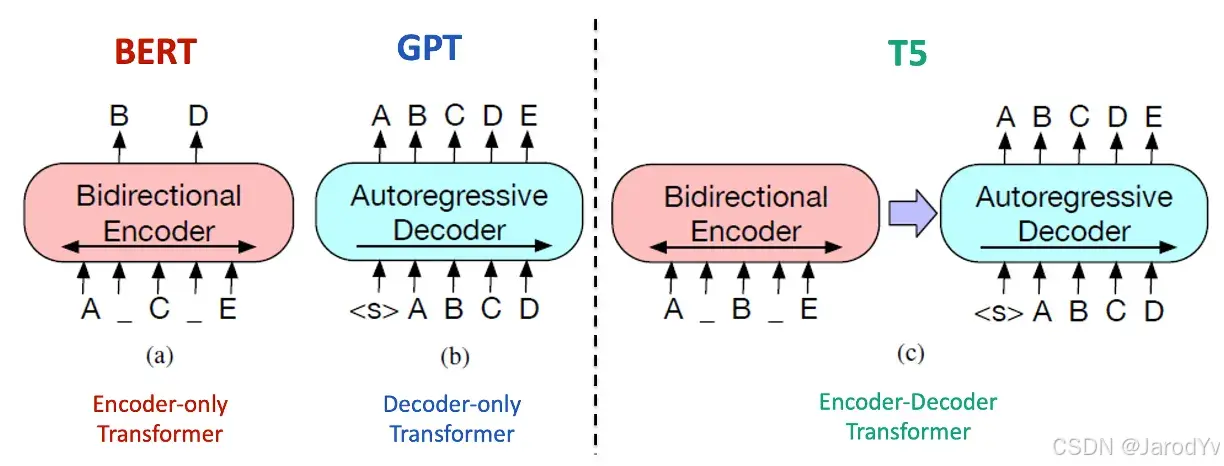
图 34. BERT vs. GTP vs. T5
8.3 OpenAI GPT 的发展历程
OpenAI 的生成式预训练 Transformer (Generative Pre-trained Transformer, GPT) 系列模型自 2018 年问世以来,极大地推动了自然语言处理 (Natural Language Processing, NLP) 领域的发展。每一代模型都在前一代的基础上进行改进,引入了更大规模的模型和增强的功能。以下是每个版本的详细概述。
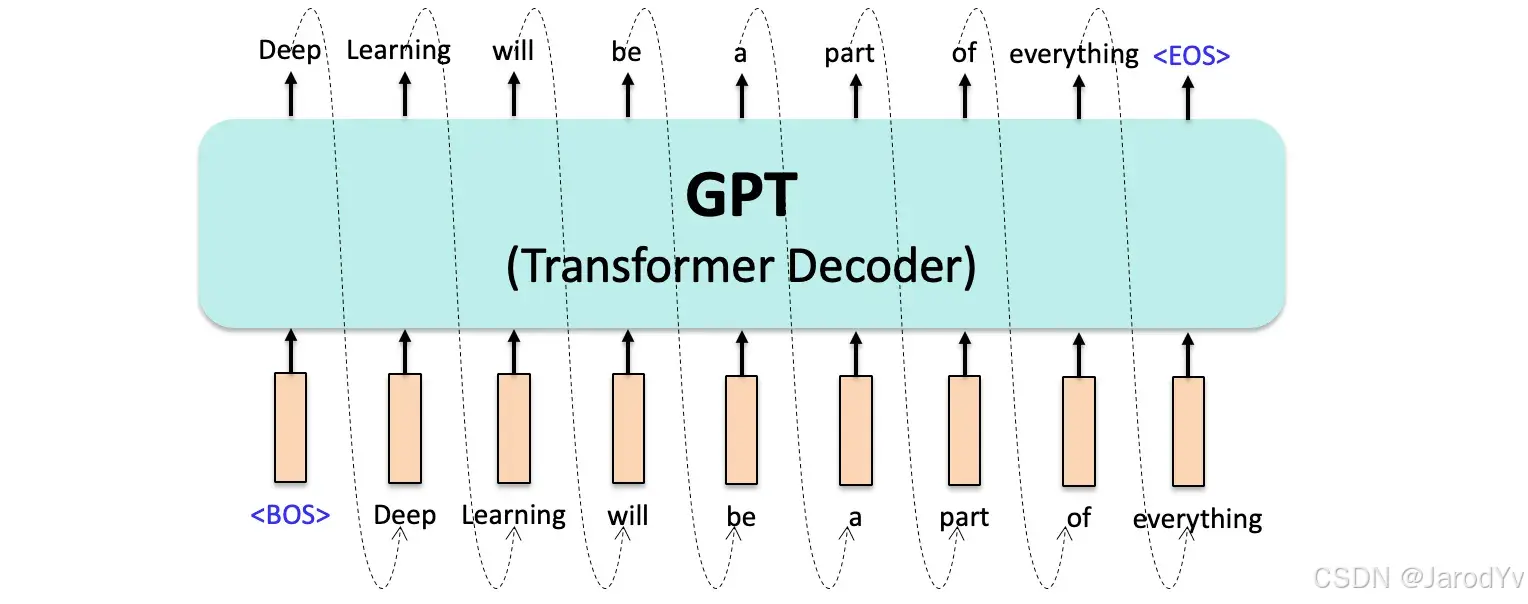
图 35. GPT 的自回归语言模型架构旨在根据之前输入的 Token 预测序列中的下一个 Token
- GPT (2018): 原始的 GPT 模型于 2018 年推出,作为一个仅使用自回归解码器的变换器,拥有 1.17 亿个参数。它被设计用于预测序列中的下一个 Token(词),展示了在理解和生成类人文本方面的强大能力。这个基础模型为后续生成式语言模型的发展奠定了基础,展示了无监督学习从大型文本语料库中获取信息的潜力。
- GPT-2 (2019): 2019 年发布的 GPT-2 在模型规模和能力上实现了显著飞跃,参数数量扩大到 15 亿个。这个版本表现出一些新兴能力,如零样本任务执行,即可以在没有专门训练的情况下执行任务。然而,它生成连贯但有时误导性文本的能力引发了关于潜在滥用的道德担忧,特别是在生成假新闻或错误信息方面。
- GPT-3 (2020): GPT-3 于 2020 年推出,进一步将模型规模扩大到惊人的 1750 亿个参数。该模型在少样本学习方面表现出卓越的能力,即可以根据提示中提供的极少量示例适应各种任务。其生成类人文本的能力使其成为许多应用的多功能工具,包括内容创作、代码辅助和对话代理。GPT-3 的架构使其能够在无需大量微调的情况下执行广泛的 NLP 任务,巩固了其作为当时最强大语言模型之一的地位。
- ChatGPT (2022): 这是一个经过微调的 GPT-3.5 模型,通过人类反馈强化学习 (Reinforcement Learning from Human Feedback, RLHF) 进行优化,擅长处理后续问题和维护上下文,通过指令调优和用户偏好数据使响应更符合用户意图。
- GPT-4 (2023): GPT-4 于 2023 年发布,继续在能力和参数数量上进行扩展,尽管其架构和参数数量的具体细节目前尚未完全公开。预计将在之前几代模型的表现上进一步提升,特别是在推理能力和理解复杂上下文的能力方面。
- GPT-o1 (2024):这一版本的 GPT 与之前所有版本有了本质区别,它开创性地引入了人类的慢思考+思维链模式,将大模型从越来越离谱的参数内卷中解救出来,开辟了AI发展的新方向。GPT-o1 显著提升了逻辑推理能力,使其在数学、科研、代码等领域的表现有了质的飞跃。在若干基准测试中,GPT-o1 展现出的能力已经与博士生相当。
8.4 其他知名大语言模型
随着越来越多优秀的大型语言模型(LLM)的涌现,人工智能领域得到了极大的丰富。这些模型各具特色,为人工智能技术带来了新的进展。以下是一些知名大语言模型的概况:
- Anthropic 的 Claude (2022): 该模型注重 AI 输出的安全性和伦理问题,致力于与人类价值观保持一致。
- Meta 的 LLaMA (2023): 提供多种规模的模型,以满足不同的计算需求,在自然语言处理的基准测试中表现卓越。
- Mistral.AI 的 Mistral (2023): 兼顾高性能和资源效率,适合于实时应用,专注于开源 AI 解决方案。
- 阿里巴巴的 Qwen (2023): 专为创建高质量的英中双语 AI 模型而设计,促进跨语言应用并推动创新。
- Microsoft 的 Phi (2023): 强调在各种应用中的多功能性和集成能力,采用先进的训练技术以提升上下文理解和用户交互。
- Google 的 Gemma 系列 (2024): 这些轻量级的开放模型应用于多种领域,包括文本生成、摘要和信息提取,注重性能和效率。
更多大语言模型及其能力评估参加下图
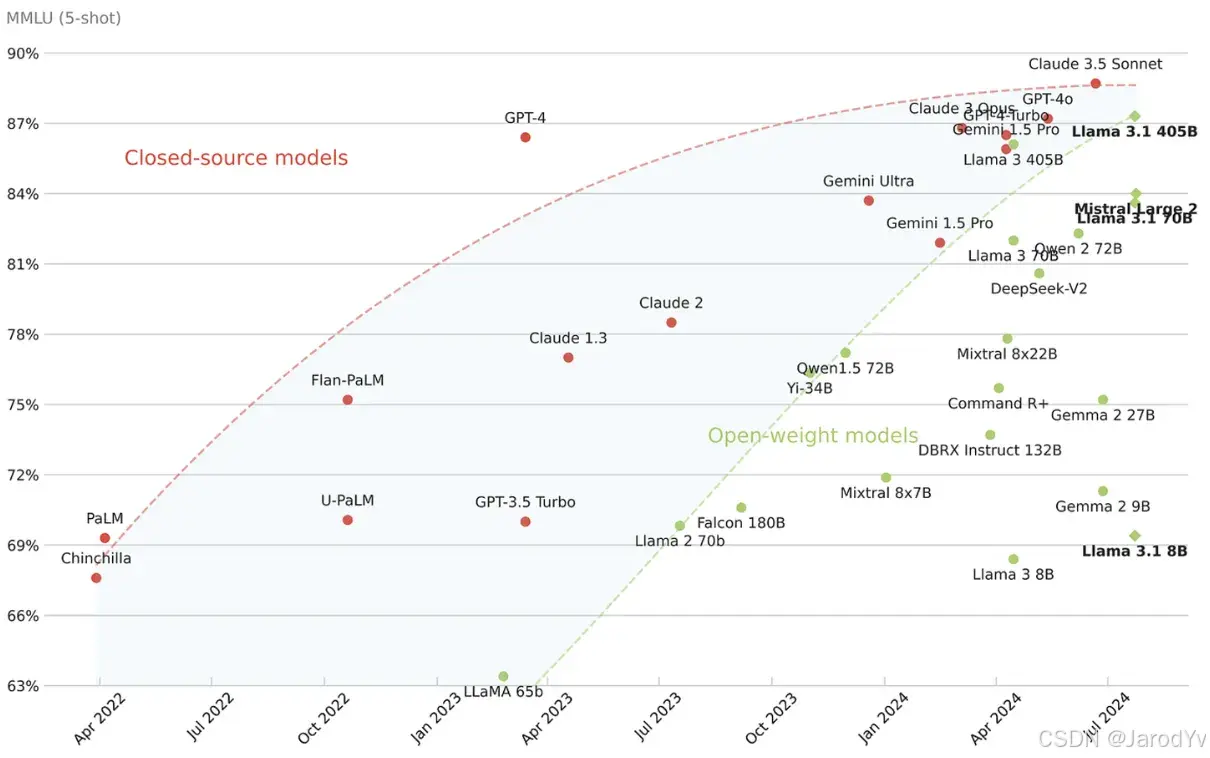
图 36. 开源模型和闭源模型的性能
9. 多模态模型 (2023 – 现在)
9.1 GPT-4V (2023) 和 GPT-4o (2024)
-
GPT-4V (2023) 是 AI 发展中的重要一步,它将多模态功能集成到已经强大的文本模型中。它不仅能够处理和生成文本,还可以处理和生成图像内容,为更全面的 AI 交互奠定了基础。
-
GPT-4o (2024) 是从 GPT-4V 演变而来的,通过复杂的上下文理解来增强多模态集成。与其前身相比,它在不同媒体之间提供了更好的连贯性,能够从文本提示生成更高级的图像,并基于视觉输入进行更精细的推理。此外,GPT-4o 通过高级训练机制实现伦理对齐,确保其输出不仅准确,而且负责任,并与人类价值观保持一致。
9.2 Google’s Gemini (2023 – 现在)
-
Gemini Pro (2023): Google 的 Gemini 推出了一系列为多模态任务设计的模型,集成了文本、图像、音频和视频处理。特别是,Gemini Pro 因其可扩展性和效率而脱颖而出,使高级 AI 能够应用于从实时分析到跨不同媒体格式的复杂内容生成等多个领域。
-
Gemini Ultra 和 Nano (2023): Gemini 模型包括适用于不同规模应用的 Ultra 和 Nano 版本,能够执行需要跨多种数据类型理解的任务。它们在视频摘要、多模态翻译和互动学习环境等任务中表现出色,体现了 Google 在推动 AI 在多媒体环境中应用的决心。
9.3 Claude 3.0 和 Claude 3.5 (2023 – 现在)
-
Claude 3.0 (2023) 由 Anthropic 推出,该模型专注于提高 AI 响应的安全性和可靠性,在上下文理解和伦理考虑方面进行了改进。它被设计得更具对话性和辅助性,同时严格遵循避免有害或偏见输出的原则。
-
Claude 3.5 (2024) 进一步提升了 Claude 3.0 的能力,在复杂任务中的表现更佳,处理效率更高,并且在用户请求的细节处理上更加细致。这个版本还强调多模态交互,虽然它主要在文本和逻辑任务中表现突出,但在处理视觉或其他感官输入方面也展现出新兴能力,提供更为综合的用户体验。
9.4 LLaVA (2023)
-
LLaVA (Large Language and Vision Assistant) 是一种创新的多模态 AI (Multimodal AI) 方法,将语言理解与视觉处理结合在一起。LLaVA 于 2023 年开发,能够解读图像并将其与文本内容相联系,使其可以回答关于图像的问题、描述视觉内容,甚至根据视觉线索生成文本。其架构充分利用 Transformer 模型的优势,在需要同时具备视觉和语言理解的任务中实现了最先进的性能。这个模型因其开源特性而备受关注,鼓励在多模态 AI 应用领域进行更多的研究和开发。
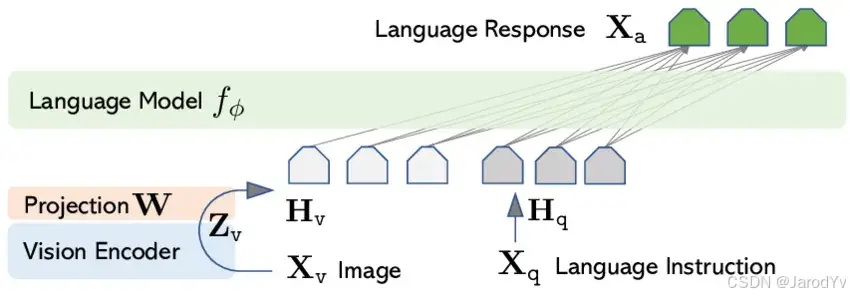
图 37. LLaVA 架构
这些模型的出现标志着 AI 系统的转变,这些系统不仅能够理解和生成文本,还能解释和创造跨多种模态的内容,更加贴近人类的认知能力。这种 AI 模型的发展推动了更具互动性和直观性的应用程序,它们能够结合不同的感官输入来处理现实世界中的场景,从而拓宽了 AI 在日常生活、研究和工业应用中的可能性。
10. 扩散模型 (2015 – 现在)
扩散模型已经成为生成模型中一个重要的类别,它为从复杂数据分布中生成高保真样本提供了一种全新的方法。与传统模型如 GAN 和 VAE 不同,扩散模型采用渐进去噪技术,并在许多应用中表现出色。
10.1 扩散模型简介 (2015)
扩散模型的基础由 Sohl-Dickstein 等人于 2015 年在他们的论文中奠定。他们提出了一种生成过程,即通过逆转逐步添加的噪声,可以将噪声还原为结构化数据。

图 38. 扩散模型原理概要
扩散模型的关键特性:
- 去噪过程: 这些模型通过逐步添加噪声(前向过程),并学习如何逆转该过程(反向过程),以有效去噪并生成样本。
- 马尔可夫链: 这两个过程都被构建为马尔可夫链,每个前向步骤添加高斯噪声,模型学习如何在反向过程中去除这些噪声。
- 训练目标: 目标是在每一步中最小化预测噪声与实际噪声之间的差异,优化一种证据下界(ELBO)的形式。
- 稳定性和鲁棒性: 它们比 GAN 提供更好的稳定性,避免了模式崩溃等问题,从而能够持续生成多样化的高质量输出。
关于扩散模型的详细介绍,请参考《Diffusion Model 深入剖析》。
10.2 扩散模型的发展 (2020 – 现在)
-
去噪扩散概率模型 (Denoising Diffusion Probabilistic Models, DDPM) (2020): 改进了扩散过程,在图像合成领域设立了新的标杆。
-
去噪扩散隐式模型 (Denoising Diffusion Implicit Models, DDIM) (2021): 通过非马尔可夫采样提高了效率,使生成过程更加灵活。
-
基于分数的生成模型 (2021): 通过使用随机微分方程提高了样本生成的效率。
-
潜在扩散模型 (Latent Diffusion Model) (2022): 成为流行的文本到图像生成系统(如 Stable Diffusion)的基础,显著推动了 AI 生成图像领域的进步,并为更易于访问和高效的生成式 AI 工具铺平了道路。关于潜在扩散模型和 Stable Diffusion 的详细介绍,请参见 《Stable Diffusion 超详细讲解》 和 《Stable Diffusion原理详解》。

图 39. 潜在扩散模型架构
10.3 文生图模型
-
DreamBooth (2022): 允许在少量特定主题的图像上训练扩散模型,从而实现个性化的图像生成。
-
LoRA (2022): 代表低秩适应,是一种通过添加少量参数来微调扩散模型的技术,使其更容易适应特定任务或数据集。
-
ControlNet (2023): 通过添加如草图或深度图等输入来控制扩散模型,从而对生成图像提供更多的控制。
-
FLUX.1 (2024): Black Forest Lab 推出了 FLUX.1,这是一种用于 AI 图像生成的先进扩散模型,具备卓越的速度、质量和响应提示的能力。FLUX.1 提供三个版本——Schnell、Dev 和 Pro,并采用了整流流变换器等创新技术,能够生成高度逼真的图像。FLUX.1 还可以生成文字并精准处理手指和脚趾等细节,是一个全面的图像生成器。
-
Multi-SBoRA (2024): Multi-SBoRA 是一种为多个概念定制扩散模型的新方法。它使用正交标准基向量来构建低秩矩阵进行微调,允许区域性和非重叠的权重更新,从而减少跨概念的干扰。这种方法保留了预训练模型的知识,减少了计算开销,并提高了模型的灵活性。实验结果显示,Multi-SBoRA 在多概念定制中表现优异,保持了独立性,并减轻了串扰效应。
10.4 文生视频模型
2024 年 2 月,OpenAI 发布了 Sora 文生视频模型。凭借惊艳的视频生成质量,Sora 一经发布就受到各行各业的追捧和关注。尽管在 Sora 之前已经有好几个文生视频模型,但 Sora 的发布被普遍认为拉开了文生视频的大幕。
Sora vs. Pika vs. RunwayML vs. Stable Video 生成视频效果对比
很明显可以看出 Sora 无论从分辨率、时长、精细度和对真实世界的还原程度上都远远好于其他模型。下表给出了详细的对比。

图 40. Sora vs. 早期文生视频模型
然而,Sora 发布后迟迟没有正式上线。全网苦等10个月,Sora 终于在 2024 年 12 月 10 日正式上线。在这 10 个月期间,国产文生视频模型迅速崛起,其中 MiniMax 的海螺和快手的可灵的视频生成质量比肩甚至超越 Sora。
| 名称 | 公司 | 单次生成秒数 | 是否免费 | 生成方式 | 最低月付费 |
|---|---|---|---|---|---|
| 可灵 | 快手 | 5s | 限制免费使用次数 | 文生视频、图生视频 | 66元 |
| 即梦 | 字节 | 5s | 限制免费使用次数 | 文生视频、图生视频 | 69元 |
| 海螺 | MiniMax | 6s | 限制免费使用次数 | 文生视频、图生视频 | 68元 |
| Vidu | 生数科技 | 4s | 限制免费使用次数 | 文生视频、图生视频 | 9.9美元 |
| 智谱清言 | 智谱科技 | 6s | 没有限制 | 文生视频、图生视频 | 免费 |
| 通义万相 | 阿里 | 6s | 没有限制 | 文生视频、图生视频 | 免费 |
| FilmAction | 瀚皓科技 | 5s | 限制免费使用次数 | 图生视频 | 50元300电影币 |
| 白日梦 | 光魔科技 | 最长6分钟 | 限制免费使用次数 | 图生视频 | 29元 |
| Sora | OpenAl | 5s、20s | 付费使用 | 文生视频、图生视频 | 20美元 |
| Runway | Runway | 10s | 限制免费使用次数 | 文生视频、图生视频 | 15美元 |
表 1. 主流文生视频模型一览表
相信 2025 年文生视频将会是各大 AI 企业主要争夺的战场。
11. 尾声
至此,我们的 AI 简史之旅就要接近尾声了。通过对 AI 发展的回顾,我们可以发现人工智能 (AI) 和深度学习的发展历史充满了突破性的进步和变革性的创新。从早期的简单神经网络到复杂的网络架构,从卷积神经网络 (CNN)、递归神经网络 (RNN) 到现在流行的 Transformer 和扩散模型,这些技术已经彻底改变了许多领域。
最近的技术进步催生了大型语言模型和多模态模型,例如 OpenAI 的 GPT-4o、Google 的 Gemini Pro、Antropic 的 Claude 3.5 Sonnet 和 Meta 的 LLaMA3.1 等,它们在自然语言处理和多模态能力方面表现出色。此外,生成式 AI (Generative AI) 的突破,包括文本到图像和文本到视频生成模型如 Midjourney、DALL-E 3、Stable Diffusion、FLUX.1 和 Sora,极大地拓展了 AI 的创造潜力。
随着研究继续致力于开发更高效、可解释和功能强大的模型,AI 和深度学习对社会和技术的影响将不断加深。这些技术进步不仅推动了传统行业的创新,还为创造性表达、问题解决和人机协作开辟了新可能。
然而,深度学习并不是实现 AI 的唯一途径或最佳途径。符号 AI、强化学习和神经符号 AI 各自具有独特优势,并能弥补深度学习在可解释性和计算资源需求方面的不足。对 AI 的全面理解应涵盖这些多样化的方法。
AI 的未来在于多种方法的协同效应。随着研究的深入,构建多元化的 AI 技术生态系统将确保其平衡和有效的发展,从而造福社会和科技领域。
评论(0)